Trusted Worldwide Questions & Answers
CompTIA DA0-001 Dumps - Pass CompTIA Data+ Certification Exam in First Attempt 2026
The CompTIA DA0-001 - CompTIA Data+ Certification Exam is designed for candidates who want to validate their skills in data-focused roles. It belongs to the CompTIA Data+ certification and focuses on practical knowledge across data concepts, analysis, visualization, and governance. This exam matters for professionals who work with data and need to demonstrate the ability to turn information into meaningful business insight.
| # | Exam Topics | Sub-Topics | Approximate Weightage (%) |
|---|---|---|---|
| 1 | Data Concepts and Environments | Data types and structures, data lifecycle, data sources, data environments | 20% |
| 2 | Data Mining | Data collection methods, pattern identification, data extraction, basic trend analysis | 20% |
| 3 | Data Analysis | Descriptive analysis, data cleaning, interpretation, statistical basics | 25% |
| 4 | Visualization | Chart selection, dashboard basics, visual storytelling, effective presentation | 20% |
| 5 | Data Governance, Quality, and Controls | Data quality checks, controls, validation, governance principles | 15% |
The exam tests how well candidates can work with data in real-world scenarios, not just memorize terms. You should expect questions that measure your understanding of core concepts, practical analysis skills, visualization choices, and data governance awareness. Success depends on both knowledge depth and the ability to apply concepts accurately under exam conditions.
How QA4Exam.com Helps You Pass
QA4Exam.com offers Exam PDF material with actual questions and answers for the CompTIA DA0-001 exam, along with an Online Practice Test that helps you study in a structured way. The practice test gives you a real exam simulation so you can get familiar with the format and improve your time management. The questions are updated and the answers are verified, which helps you focus on the most relevant exam content. Using both formats together can strengthen your confidence and improve your chances of passing the CompTIA DA0-001 exam on your first attempt.
Frequently Asked Questions
What is the CompTIA Data+ Certification Exam?
The CompTIA Data+ Certification Exam is the CompTIA DA0-001 exam, which validates knowledge in data concepts, analysis, visualization, and governance.
Who should take the DA0-001 exam?
It is intended for candidates who want to prove their ability to work with data and support data-driven decision-making in professional environments.
Is the CompTIA DA0-001 exam difficult?
The exam can be challenging because it covers multiple data domains and expects practical understanding, but focused preparation can make it manageable.
Can I pass with only braindumps?
Braindumps alone are not the best approach. You should use them with study and practice so you understand the concepts behind the answers.
Do I need hands-on experience for DA0-001?
Hands-on experience is helpful because the exam focuses on practical data skills, interpretation, and decision-making across real scenarios.
Are QA4Exam.com dumps enough to pass in the first attempt?
QA4Exam.com provides Exam PDF and Online Practice Test resources that can greatly improve preparation, especially when used to review questions, answers, and exam style before test day.
What is included in the QA4Exam.com practice test format?
The Online Practice Test is designed to simulate the exam experience, helping you practice under timed conditions and check your readiness with verified answers.
What if I need to retake the exam?
If you do not pass on the first attempt, you can review the topics again, practice more, and return with better preparation and stronger time management.
The questions for DA0-001 were last updated on Jul 22, 2026.
- Viewing page 1 out of 73 pages.
- Viewing questions 1-5 out of 363 questions
Which of the following is an example of structured data?
A credit card number is an example of structured data, which is a type of data that conforms to a data model, has a well-defined structure, follows a consistent order, and can be easily accessed and used by a person or a computer program. A credit card number consists of 16 digits that are divided into four groups of four digits each, separated by spaces or hyphens. The first six digits indicate the issuer identification number, the next nine digits indicate the account number, and the last digit is a check digit that validates the number.A credit card number can be stored and processed in a structured format, such as a database or a spreadsheet1.
Given the information in the following tables:
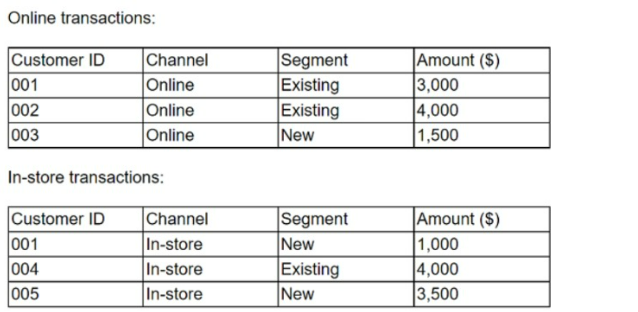
Which of the following describes merging these tables to create a master file that includes all transactions for both online and in-store sales?
Merging tables to create a master file that includes all transactions for both online and in-store sales is best described as data consolidation. This process involves combining data from various sources into a single, unified dataset. Data consolidation is essential for providing a comprehensive view of all transactions, which can be used for analysis, reporting, and decision-making purposes.
You would like to measure how well an organization is achieving its goals.
What type of analysis should you perform?
Performance analysis is the technique of studying or comparing the performance of a specific situation in contrast to the aim and yet executed. In Human Resources, performance analysis can help to review an employee's contribution towards a project or assignment, which they allotted him or her.
Which of the following data cleansing issues will be fixed when a DISTINCT function is applied?
This is because duplicate data refers to data that is repeated or copied in a data set, which can affect the quality and validity of the analysis. A DISTINCT function is a type of function that removes duplicate values from a column or a table, leaving only unique values. For example, a DISTINCT function in SQL that can achieve this is:

The other data cleansing issues will not be fixed by applying a DISTINCT function. Here is why:
Missing data refers to data that is absent or incomplete in a data set, which can affect the accuracy and reliability of the analysis. A DISTINCT function does not help with missing data, because it does not fill in or impute the missing values.
Redundant data refers to data that is unnecessary or irrelevant for the analysis, which can affect the efficiency and performance of the analysis. A DISTINCT function does not help with redundant data, because it does not remove or filter out the redundant values.
Invalid data refers to data that is incorrect or inaccurate in a data set, which can affect the validity and reliability of the analysis. A DISTINCT function does not help with invalid data, because it does not validate or correct the invalid values.
The ACME Corporation hired an analyst to detect data quality issues in their Excel documents. Which of the following are the most common issues? (Select TWO)
1. Duplicates
2. Misspellings
The most common data quality issues are difficult to resolve in Excel because of their rigidity. It forces analysts to do a ton of manual work, which results in a high probability of an error being introduced to the data set. Those common issues include:
- Blanks
- Nulls
- Outliers
- Duplicates
- Extra spaces
- Misspellings
- Abbreviations and domain-specific variations
- Formula error codes
When introduced, these errors can skew or even invalidate the resulting analysis. A smart tool would minimize the possibility of error by automating the manual work. In Excel, you might look for data quality issues in one of two ways. First, you might use auto filters on specific columns to scan for anomalies and blanks or you might use a pivot table to find gaps and discrepancies.
In either case, you're scanning for the anomalies yourself. Suffice it to say that's not a very efficient process. It also means accuracy is only as good as the analyst's eye, so the probability of error varies throughout the day.
Unlock All Questions for CompTIA DA0-001 Exam
Full Exam Access, Actual Exam Questions, Validated Answers, Anytime Anywhere, No Download Limits, No Practice Limits
Get All 363 Questions & Answers