Trusted Worldwide Questions & Answers
Microsoft DP-100 Dumps - Pass Designing and Implementing a Data Science Solution on Azure in 2026
The Microsoft DP-100 exam, "Designing and Implementing a Data Science Solution on Azure," is part of the Azure Data Scientist Associate certification path. It is designed for data science professionals who build, train, and manage machine learning solutions on Microsoft Azure. This exam matters because it validates practical skills in preparing data, running experiments, deploying models, and working with AI workloads in a cloud environment.
Candidates who earn this certification show they can design reliable data science solutions and apply Azure tools to real business problems. It is a strong credential for data scientists, machine learning engineers, and analytics professionals who want to prove their Azure expertise.
| # | Exam Topics | Sub-Topics | Approximate Weightage (%) |
|---|---|---|---|
| 1 | Design and prepare a machine learning solution | Define problem scope, select compute and workspace resources, prepare Azure Machine Learning environment, plan experiment workflow | 25 |
| 2 | Explore data, and run experiments | Load and inspect data, perform data profiling, analyze features, run and compare experiments | 25 |
| 3 | Train and deploy models | Train models, tune hyperparameters, evaluate model performance, register and deploy models | 30 |
| 4 | Optimize language models for AI applications | Work with language models, adapt models for AI use cases, evaluate outputs, improve application relevance and response quality | 20 |
This exam tests more than theory. It measures how well candidates can apply data science concepts in Azure, interpret results, manage experiments, and choose the right approach for model training and deployment. A strong candidate should understand both the practical workflow and the Azure services involved in delivering a complete machine learning solution.
How QA4Exam.com Helps You Pass
QA4Exam.com offers an Exam PDF with actual questions and answers plus an Online Practice Test to help you prepare for the Microsoft DP-100 exam with confidence. The practice test gives you a real exam simulation so you can get familiar with the question style, pacing, and pressure of the actual test. The updated questions and verified answers help you study with focus and reduce guesswork during preparation. You also get a better sense of time management, which is important for passing on the first attempt. With both formats, you can review repeatedly and strengthen your readiness before exam day.
Frequently Asked Questions
1. Who should take the Microsoft DP-100 exam?
The DP-100 exam is intended for professionals who work with data science and machine learning on Azure, including those pursuing the Azure Data Scientist Associate certification.
2. Is the DP-100 exam difficult?
It can be challenging because it tests practical Azure data science skills, not just memorized facts. Candidates need a clear understanding of training, deployment, experimentation, and solution design.
3. Can I pass DP-100 with only braindumps?
Braindumps alone are not the best approach. They can help with question familiarity, but hands-on understanding and structured review are important for real exam success.
4. Do I need hands-on experience to pass DP-100?
Hands-on experience is highly recommended because the exam focuses on practical skills in Azure machine learning, experimentation, and model deployment.
5. Are QA4Exam.com dumps and practice tests enough to prepare?
QA4Exam.com dumps and the Online Practice Test are strong preparation tools, especially when used to review updated questions and verify answers. For best results, they should be combined with understanding the exam topics and practicing key concepts.
6. How do QA4Exam.com practice tests help with first-attempt success?
They help you simulate the real exam, learn the question pattern, and practice time management. This makes it easier to stay calm and answer efficiently on exam day.
7. What format do the QA4Exam.com materials come in?
QA4Exam.com provides an Exam PDF with questions and answers and an Online Practice Test format for interactive preparation.
The questions for DP-100 were last updated on Jul 23, 2026.
- Viewing page 1 out of 101 pages.
- Viewing questions 1-5 out of 506 questions
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You train and register an Azure Machine Learning model.
You plan to deploy the model to an online endpoint.
You need to ensure that applications will be able to use the authentication method with a non-expiring artifact to access the model.
Solution:
Create a managed online endpoint and set the value of its auto_mode parameter to key. Deploy the model to the inline endpoint.
Does the solution meet the goal?
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You create an Azure Machine Learning service datastore in a workspace. The datastore contains the following files:
* /data/2018/Q1 .csv
* /data/2018/Q2.csv
* /data/2018/Q3.csv
* /data/2018/Q4.csv
* /data/2019/Q1.csv
All files store data in the following format:
id,f1,f2,l
1,1,2,0
2,1,1,1
3.2.1.0
You run the following code:
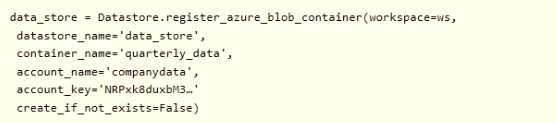
You need to create a dataset named training_data and load the data from all files into a single data frame by using the following code:

Solution: Run the following code:

Does the solution meet the goal?
Use two file paths.
Use Dataset.Tabular_from_delimeted as the data isn't cleansed.
Note:
A TabularDataset represents data in a tabular format by parsing the provided file or list of files. This provides you with the ability to materialize the data into a pandas or Spark DataFrame so you can work with familiar data preparation and training libraries without having to leave your notebook. You can create a TabularDataset object from .csv, .tsv, .parquet, .jsonl files, and from SQL query results.
https://docs.microsoft.com/en-us/azure/machine-learning/how-to-create-register-datasets
You need to implement a scaling strategy for the local penalty detection data.
Which normalization type should you use?
Post batch normalization statistics (PBN) is the Microsoft Cognitive Toolkit (CNTK) version of how to evaluate the population mean and variance of Batch Normalization which could be used in inference Original Paper.
In CNTK, custom networks are defined using the BrainScriptNetworkBuilder and described in the CNTK network description language 'BrainScript.'
Scenario:
Local penalty detection models must be written by using BrainScript.
https://docs.microsoft.com/en-us/cognitive-toolkit/post-batch-normalization-statistics
You must store data in Azure Blob Storage to support Azure Machine Learning.
You need to transfer the data into Azure Blob Storage.
What are three possible ways to achieve the goal? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
You can move data to and from Azure Blob storage using different technologies:
Azure Storage-Explorer
AzCopy
Python
SSIS
https://docs.microsoft.com/en-us/azure/machine-learning/team-data-science-process/move-azure-blob
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are analyzing a numerical dataset which contains missing values in several columns.
You must clean the missing values using an appropriate operation without affecting the dimensionality of the feature set.
You need to analyze a full dataset to include all values.
Solution: Remove the entire column that contains the missing data point.
Does the solution meet the goal?
Use the Multiple Imputation by Chained Equations (MICE) method.
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3074241/
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/clean-missing-data
Unlock All Questions for Microsoft DP-100 Exam
Full Exam Access, Actual Exam Questions, Validated Answers, Anytime Anywhere, No Download Limits, No Practice Limits
Get All 506 Questions & Answers