Trusted Worldwide Questions & Answers
Qlik QSDA2024 Dumps - Pass Qlik Sense Data Architect Certification Exam - 2024 in First Attempt 2026
The Qlik QSDA2024 - Qlik Sense Data Architect Certification Exam - 2024 is part of the Qlik Sense certification track and is designed for candidates who work with data architecture, data preparation, and model design in Qlik Sense. It is a strong choice for professionals who want to validate their ability to build reliable data solutions and support analytics projects. This exam matters because it confirms practical knowledge that helps teams connect data, shape models, and validate results with confidence. Earning this certification can strengthen your credibility as a data architect in Qlik environments.
Exam Topics and Approximate Weightage
| # | Exam Topics | Sub-Topics | Approximate Weightage (%) |
|---|---|---|---|
| 1 | Identify Requirements | Business needs analysis, data source review, reporting goals, solution scope | 15% |
| 2 | Data Connectivity | Connecting to data sources, loading data, connection types, source access considerations | 20% |
| 3 | Data Model Design | Associations, keys and fields, star schema concepts, data model optimization | 25% |
| 4 | Data Transformations | Data cleansing, field manipulation, script-based transformation, shaping data for analysis | 25% |
| 5 | Validation | Checking results, verifying associations, troubleshooting load issues, confirming output accuracy | 15% |
This exam tests how well candidates can turn business requirements into a working Qlik Sense data architecture. It focuses on practical knowledge of connectivity, modeling, transformation, and validation rather than simple memorization. Candidates should be ready to apply concepts to real scenarios and choose the right approach for building dependable data solutions.
How QA4Exam.com Helps You Pass
QA4Exam.com offers the Qlik QSDA2024 Exam PDF with actual questions and answers, giving you a focused way to study the exam style and core topics. The Online Practice Test helps you experience a real exam simulation, so you can build confidence before test day. With up-to-date questions and verified answers, you can review the most relevant material and reduce guesswork in your preparation. The practice format also helps you improve time management and learn how to handle questions under exam pressure. Together, these resources are designed to help you prepare efficiently and aim for a first-attempt pass.
Frequently Asked Questions
1. Who is the Qlik Sense Data Architect Certification Exam - 2024 for?
It is for candidates who want to validate skills in data connectivity, data model design, transformations, and validation within Qlik Sense.
2. Is the QSDA2024 exam difficult?
The exam can be challenging because it tests practical understanding of Qlik Sense data architecture, not just theory. Preparation and hands-on familiarity are important.
3. Can I pass QSDA2024 with only braindumps?
Braindumps alone are not the best approach. They are more effective when used with review, understanding, and practice so you can handle different question styles.
4. Do I need hands-on experience with Qlik Sense?
Yes, hands-on experience is very helpful because the exam focuses on real data architecture tasks such as modeling, transformations, and validation.
5. Are the QA4Exam.com dumps enough to prepare for the first attempt?
They are a strong preparation tool when used properly. The Exam PDF and Online Practice Test help you study actual questions, verify answers, and practice under timed conditions.
6. What is included in the QA4Exam.com study format?
QA4Exam.com provides an Exam PDF with actual questions and answers plus an Online Practice Test that simulates the exam experience.
7. How do the practice tests help with passing on the first attempt?
They help you learn the question format, improve time management, and check your readiness before the real exam, which supports a first-attempt strategy.
The questions for QSDA2024 were last updated on Jul 20, 2026.
- Viewing page 1 out of 10 pages.
- Viewing questions 1-5 out of 50 questions
The data architect has been tasked with building a sales reporting application.
* Part way through the year, the company realigned the sales territories
* Sales reps need to track both their overall performance, and their performance in their current territory
* Regional managers need to track performance for their region based on the date of the sale transaction
* There is a data table from HR that contains the Sales Rep ID, the manager, the region, and the start and end dates for that assignment
* Sales transactions have the salesperson in them, but not the manager or region.
What is the first step the data architect should take to build this data model to accurately reflect performance?
In the provided scenario, the sales territories were realigned during the year, and it is necessary to track performance based on the date of the sale and the salesperson's assignment during that period. The IntervalMatch function is the best approach to create a time-based relationship between the sales transactions and the sales territory assignments.
IntervalMatch: This function is used to match discrete values (e.g., transaction dates) with intervals (e.g., start and end dates for sales territory assignments). By matching the transaction dates with the intervals in the HR table, you can accurately determine which territory and manager were in effect at the time of each sale.
Using IntervalMatch, you can generate point-in-time data that accurately reflects the dynamic nature of sales territory assignments, allowing both sales reps and regional managers to track performance over time.
A data architect needs to upload data from ten different sources, but only if there are any changes after the last reload. When data is updated, a new file is placed into a folder mapped to E:\486396169. The data connection points to this folder.
The data architect plans a script which will:
1. Verify that the file exists
2. If the file exists, upload it Otherwise, skip to the next piece of code.
The script will repeat this subroutine for each source. When the script ends, all uploaded files will be removed with a batch procedure. Which option should the data architect use to meet these requirements?
In this scenario, the data architect needs to verify the existence of files before attempting to load them and then proceed accordingly. The correct approach involves using the FileExists() function to check for the presence of each file. If the file exists, the script should execute the file loading routine. The FOR EACH loop will handle multiple files, and the IF statement will control the conditional loading.
FileExists(): This function checks whether a specific file exists at the specified path. If the file exists, it returns TRUE, allowing the script to proceed with loading the file.
FOR EACH: This loop iterates over a list of items (in this case, file paths) and executes the enclosed code for each item.
IF: This statement checks the condition returned by FileExists(). If TRUE, it executes the code block for loading the file; otherwise, it skips to the next iteration.
This combination ensures that the script loads data only if the files are present, optimizing the data loading process and preventing unnecessary errors.
A data architect needs to load large amounts of data from a database that is continuously updated.
* New records are added, and existing records get updated and deleted.
* Each record has a LastModified field.
* All existing records are exported into a QVD file.
* The data architect wants to load the records into Qlik Sense efficiently.
Which steps should the data architect take to meet these requirements?
When dealing with a database that is continuously updated with new records, updates, and deletions, an efficient data load strategy is necessary to minimize the load time and keep the Qlik Sense data model up-to-date.
Explanation of Steps:
Load the existing data from the QVD:
This step retrieves the already loaded and processed data from a previous session. It acts as a base to which new or updated records will be added.
Load new and updated data from the database. Concatenate with the table loaded from the QVD:
The next step is to load only the new and updated records from the database. This minimizes the amount of data being loaded and focuses on just the changes.
The new and updated records are then concatenated with the existing data from the QVD, creating a combined dataset that includes all relevant information.
Create a separate table for the deleted rows and use a WHERE NOT EXISTS to remove these records:
A separate table is created to handle deletions. The WHERE NOT EXISTS clause is used to identify and remove records from the combined dataset that have been deleted in the source database.
Exhibit.
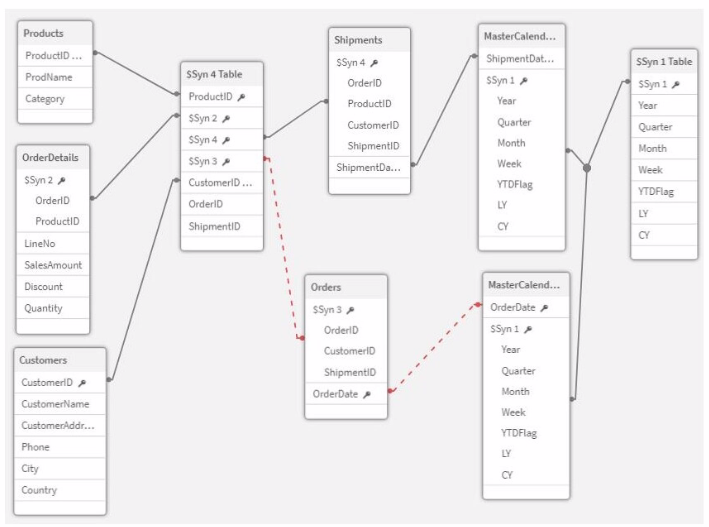
Refer to the exhibit.
A data architect is working on a Qlik Sense app the business has created to analyze the company orders and shipments.
To understand the table structure, the business has given the following summary:
* Every order creates a unique orderlD and an order date in the Orders table
* An order can contain one or more order lines one for each product ID in the order details table
* Products In the order are shipped (shipment date) as soon as they are ready and can be shipped separately
* The dates need to be analyzed separately by Year, Month, and Quarter
The data architect realizes the data model has issues that must be fixed. Which steps should the data architect perform?
In the given data model, there are several issues related to table relationships and key fields that need to be addressed to create a functional and optimized data model. Here's how each step in the chosen solution (Option C) resolves these issues:
Create a key with OrderID and ProductID in the OrderDetails table and in the Shipments table:
By creating a composite key with OrderID and ProductID, you uniquely identify each line item in both the OrderDetails and Shipments tables. This step is crucial for ensuring that each product within an order is correctly associated with its respective shipment.
Delete the ShipmentID in the Orders table:
The ShipmentID in the Orders table is redundant because the Shipments table already captures this information at a more granular level (i.e., at the product level). Removing ShipmentID avoids potential circular references or synthetic keys.
Delete the ProductID and OrderID in the Shipments table:
After creating the composite key in step 1, the individual ProductID and OrderID fields in the Shipments table are no longer necessary for joins. Removing them reduces redundancy and simplifies the table structure.
Concatenate Orders and OrderDetails:
Concatenating Orders and OrderDetails into a single table creates a unified table that contains all necessary order-related information. This helps in simplifying the model and avoiding issues related to managing separate but related tables.
Create a link table using the MasterCalendar table and create a concatenated field between OrderDate and ShipmentDate:
A link table is created to associate the combined table with the MasterCalendar. By creating a concatenated field that combines OrderDate and ShipmentDate, you ensure that both dates are properly linked to the calendar, allowing for accurate time-based analysis.
Exhibit.
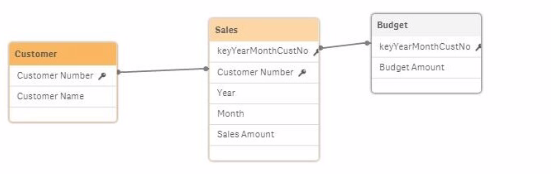
Refer to the exhibit.
The data architect needs to build a model that contains Sales and Budget data for each customer. Some customers have Sales without a Budget, and other customers have a Budget with no Sales.
During loading, the data architect resolves a synthetic key by creating the composite key.
For validation, the data architect creates a table that contains Customer, Month, Sales, and Budget columns.
What will the data architect see when selecting a month?
In the scenario where the data model is built with a composite key (keyYearMonthCustNo) to resolve synthetic keys, the following outcomes occur:
Sales and Budget Data Integration:
The composite key ensures that each combination of Year, Month, and Customer is uniquely represented in the combined Sales and Budget data.
During data selection (e.g., when a specific month is selected), Qlik Sense will show all the customer names that have either Sales or Budget data associated with that month.
Resulting Data View:
For the selected month, customers with sales records will display their Sales data. However, if the corresponding Budget data is missing, the Budget column will contain null values.
Similarly, if a customer has a Budget but no Sales data for the selected month, the Sales column will show null values.
Validation Outcome: When the data architect selects a month, they will see the following:
Customer Names and Sales records for the selected month, where the Sales column will have values and the Budget column may contain null or non-null values depending on the data availability.
Unlock All Questions for Qlik QSDA2024 Exam
Full Exam Access, Actual Exam Questions, Validated Answers, Anytime Anywhere, No Download Limits, No Practice Limits
Get All 50 Questions & Answers