Trusted Worldwide Questions & Answers
Most Recent SAP C_ABAPD_2309 Exam Dumps
Prepare for the SAP Certified Associate - Back-End Developer - ABAP Cloud Exam exam with our extensive collection of questions and answers. These practice Q&A are updated according to the latest syllabus, providing you with the tools needed to review and test your knowledge.
QA4Exam focus on the latest syllabus and exam objectives, our practice Q&A are designed to help you identify key topics and solidify your understanding. By focusing on the core curriculum, These Questions & Answers helps you cover all the essential topics, ensuring you're well-prepared for every section of the exam. Each question comes with a detailed explanation, offering valuable insights and helping you to learn from your mistakes. Whether you're looking to assess your progress or dive deeper into complex topics, our updated Q&A will provide the support you need to confidently approach the SAP C_ABAPD_2309 exam and achieve success.
The questions for C_ABAPD_2309 were last updated on Jul 20, 2026.
- Viewing page 1 out of 16 pages.
- Viewing questions 1-5 out of 81 questions
Setting a field to read-only in which object would make the field read-only in all applications of the RESTful Application Programming model?
The following code snippet defines a behaviour definition for a business object ZI_PB_APPLICATION. It sets the field APPLICATION to read-only for all applications that use this business object:
define behavior for ZI_PB_APPLICATION { field ( read only ) APPLICATION; ... }
You cannot do any of the following:
Which restrictions exist for ABAP SQL arithmetic expressions? Note: There are 2 correct answers to this question.
ABAP SQL arithmetic expressions have different restrictions depending on the data type of the operands. The following are some of the restrictions:
Floating point types and integer types can be used in the same expression, as long as the integer types are cast to floating point types using the cast function. For example,CAST ( num1 AS FLTP ) / CAST ( num2 AS FLTP )is a valid expression, where num1 and num2 are integer types.
The operator / is allowed only in floating point expressions, where both operands have the type FLTP or f. For example,num1 / num2is a valid expression, where num1 and num2 are floating point types. If the operator / is used in an integer expression or a decimal expression, a syntax error occurs.
Decimal types and integer types can be used in the same expression, as long as the expression is a decimal expression. A decimal expression has at least one operand with the type DEC, CURR, or QUAN or p with decimal places. For example,num1 + num2is a valid expression, where num1 is a decimal type and num2 is an integer type.
The operator ** is allowed only in floating point expressions, where both operands have the type FLTP or f. For example,num1 ** num2is a valid expression, where num1 and num2 are floating point types. If the operator ** is used in an integer expression or a decimal expression, a syntax error occurs.
In this nested join below in which way is the join evaluated?
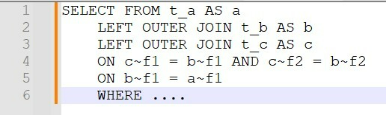
The nested join is evaluated from the top to the bottom in the order of the ON conditions. This means that the join expression is formed by assigning each ON condition to the directly preceding JOIN from left to right. The join expression can be parenthesized implicitly or explicitly to show the order of evaluation. In this case, the implicit parentheses are as follows:
SELECT * FROM (a INNER JOIN (b INNER JOIN c ON b~c = c~c) ON a~b = b~b)
This means that the first join expression is b INNER JOIN c ON b~c = c~c, which joins the columns of tables b and c based on the condition that b~c equals c~c. The second join expression is a INNER JOIN (b INNER JOIN c ON b~c = c~c) ON a~b = b~b, which joins the columns of table a and the result of the first join expression based on the condition that a~b equals b~b. The final result set contains all combinations of rows from tables a, b, and c that satisfy both join conditions.
You want to provide a short description of the data definition for developers that will be attached to the database view
Which of the following annotations would do this if you inserted it on line #27
The following code snippet uses the @EndUserText.label annotation to provide a short description of the data definition for the CDS view ZCDS_VIEW:
@AbapCatalog.sqlViewName: 'ZCDS_VIEW' @AbapCatalog.compiler.compareFilter: true @AbapCatalog.preserveKey: true @AccessControl.authorizationCheck: #CHECK @EndUserText.label: 'CDS view for flight data' 'short description for developers define view ZCDS_VIEW as select from sflight { key carrid, key connid, key fldate, seatsmax, seatsocc }
You cannot do any of the following:
Refer to the exhibit.

When accessing the subclass instance through go_super, what can you do? Note: There are 2 correct answers to this question.
When accessing the subclass instance through go_super, you can do both of the following:
You cannot do any of the following:
Unlock All Questions for SAP C_ABAPD_2309 Exam
Full Exam Access, Actual Exam Questions, Validated Answers, Anytime Anywhere, No Download Limits, No Practice Limits
Get All 81 Questions & Answers